


Seguindo a parte 2 do artigo sobre Execution Plan (planos de execução), veremos como é o funcionamento da analise e interpretação de um plano de execução no banco de dados POSTGRESQL.
Seguindo o que comumente faço para essa analise, 2 modos podemos estabelecer para essa analise :
- Plano de execução em modo texto/tabular, onde é visto de forma indentada os steps.
- Plano de execução em modo tree (arvore), onde é visto de forma grafica os steps.
Similar ao oracle database, o POSTGRESQL utilize a seguinte metodologia para interpretação de planos de execução, O plano de execução é lido de baixo para cima e da direita para a esquerda, refletindo a sequência em que o PostgreSQL executa as operações.
No PostgreSQL, os planos de execução são lidos de baixo para cima e da direita para a esquerda. Isso significa que:
- A operação mais profunda (mais aninhada) no plano é a primeira a ser executada.
- As operações externas ou superiores são executadas posteriormente, processando os dados obtidos das operações inferiores.
Essa abordagem permite entender melhor o fluxo da execução da consulta e identificar possíveis gargalos de desempenho.
Para tornar a explicação mais objetiva, vamos analisar um exemplo de query, interpretar seu plano de execução e, posteriormente, verificar possíveis otimizações para tornar a execução do SQL mais eficiente.
SELECT * FROM (
(SELECT
poi.supplier_product ->> 'supplier_product_name' AS name,
poi.price AS price,
poi.created_at AS expires_at,
poi.supplier_product ->> 'supplier_product_manufacturer' AS manufacturer,
poi.supplier_product ->> 'supplier_product_packing' AS packing,
poi.supplier_product ->> 'supplier_product_pack_quantity' AS pack_quantity,
poi.supplier_product ->> 'supplier_product_unit_purchase' AS unit_purchase,
poi.confirmed_quantity AS quantity_price,
sp.name AS name_supply,
sp.identifier AS identifier_supply,
1 AS order_by
FROM purchase_order_items poi
INNER JOIN purchase_orders po ON po.id = poi.purchase_order_id
INNER JOIN buyer_products bp ON bp.buyer_id = po.buyer_id AND
bp.code = poi.buyer_product ->> 'buyer_product_code'
INNER JOIN products p ON p.id = bp.base_product_id
INNER JOIN suppliers sp ON sp.id = po.supplier_id
WHERE bp.id = 12081956
AND poi.created_at < '2025-02-21 16:57:59.225571'
ORDER BY poi.created_at DESC
LIMIT 3
)
UNION ALL
(SELECT
bp.name,
bp.source_price AS price,
bp.created_at AS expires_at,
'' AS manufacturer,
'' AS packing,
'' AS pack_quantity,
'' AS unit_purchase,
0 AS quantity_price,
'' AS name_supply,
'' AS identifier_supply,
2 AS order_by
FROM public.buyer_products bp
INNER JOIN public.products p ON p.id = bp.base_product_id
WHERE bp.id = 12081956
AND bp.source_price IS NOT NULL
)
) b
ORDER BY order_by
LIMIT 3;Para analisar os planos de execução, utilizaremos duas ferramentas que auxiliam na visualização e interpretação dos dados. Cada ferramenta apresenta o plano de uma forma diferente, permitindo uma análise mais completa:
- Modo Tabular: Explain Depesz – Exibe o plano de execução em formato tabular, facilitando a leitura estruturada dos passos.
https://explain.depesz.com/ - Modo Árvore (Tree): Explain Dalibo – Representa o plano de execução graficamente, tornando mais intuitiva a hierarquia das operações.
https://explain.dalibo.com/
📌 Instrução: Clique nos links acima para acessar as ferramentas e seguir o procedimento de visualização dos dois métodos.
Para visualizar o plano de execução em ambos os modos, primeiro precisamos extraí-lo em formato de texto. Para isso, basta adicionar a seguinte declaração no início da query:
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS)
(...) SQL CODE (...)Essa instrução fornece informações detalhadas sobre a execução da consulta, incluindo:
- ANALYZE: Executa a query de fato e retorna estatísticas reais de tempo e quantidade de linhas processadas.
- COSTS: Exibe os custos estimados de cada operação no plano de execução.
- VERBOSE: Apresenta detalhes adicionais, como a estrutura da consulta e a relação das colunas envolvidas.
- BUFFERS: Mostra informações sobre o uso do cache de memória (buffers) durante a execução.
Abaixo, veja como o código SQL completo ficará com a inclusão do EXPLAIN na consulta.
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS )
SELECT * FROM (
(SELECT
poi.supplier_product ->> 'supplier_product_name' AS name,
poi.price AS price,
poi.created_at AS expires_at,
poi.supplier_product ->> 'supplier_product_manufacturer' AS manufacturer,
poi.supplier_product ->> 'supplier_product_packing' AS packing,
poi.supplier_product ->> 'supplier_product_pack_quantity' AS pack_quantity,
poi.supplier_product ->> 'supplier_product_unit_purchase' AS unit_purchase,
poi.confirmed_quantity AS quantity_price,
sp.name AS name_supply,
sp.identifier AS identifier_supply,
1 AS order_by
FROM purchase_order_items poi
INNER JOIN purchase_orders po ON po.id = poi.purchase_order_id
INNER JOIN buyer_products bp ON bp.buyer_id = po.buyer_id AND
bp.code = poi.buyer_product ->> 'buyer_product_code'
INNER JOIN products p ON p.id = bp.base_product_id
INNER JOIN suppliers sp ON sp.id = po.supplier_id
WHERE bp.id = 12081956
AND poi.created_at < '2025-02-21 16:57:59.225571'
ORDER BY poi.created_at DESC
LIMIT 3
)
UNION ALL
(SELECT
bp.name,
bp.source_price AS price,
bp.created_at AS expires_at,
'' AS manufacturer,
'' AS packing,
'' AS pack_quantity,
'' AS unit_purchase,
0 AS quantity_price,
'' AS name_supply,
'' AS identifier_supply,
2 AS order_by
FROM public.buyer_products bp
INNER JOIN public.products p ON p.id = bp.base_product_id
WHERE bp.id = 12081956
AND bp.source_price IS NOT NULL
)
) b
ORDER BY order_by
LIMIT 3;Após executar o comando EXPLAIN, o PostgreSQL gera um plano de execução em formato de texto. A seguir, veja um exemplo do plano gerado para esta query:
Limit (cost=120200.56..120200.57 rows=2 width=252) (actual time=207.212..207.217 rows=3 loops=1)
Output: ((poi.supplier_product ->> 'supplier_product_name'::text)), poi.price, poi.created_at, ((poi.supplier_product ->> 'supplier_product_manufacturer'::text)), ((poi.supplier_product ->> 'supplier_product_packing'::t
ext)), ((poi.supplier_product ->> 'supplier_product_pack_quantity'::text)), ((poi.supplier_product ->> 'supplier_product_unit_purchase'::text)), poi.confirmed_quantity, sp.name, sp.identifier, (1)
Buffers: shared hit=64032
-> Sort (cost=120200.56..120200.57 rows=2 width=252) (actual time=186.714..186.718 rows=3 loops=1)
Output: ((poi.supplier_product ->> 'supplier_product_name'::text)), poi.price, poi.created_at, ((poi.supplier_product ->> 'supplier_product_manufacturer'::text)), ((poi.supplier_product ->> 'supplier_product_packi
ng'::text)), ((poi.supplier_product ->> 'supplier_product_pack_quantity'::text)), ((poi.supplier_product ->> 'supplier_product_unit_purchase'::text)), poi.confirmed_quantity, sp.name, sp.identifier, (1)
Sort Key: (1)
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=64032
-> Append (cost=120195.05..120200.49 rows=2 width=252) (actual time=186.639..186.704 rows=4 loops=1)
Buffers: shared hit=64032
-> Limit (cost=120195.05..120195.06 rows=1 width=242) (actual time=186.637..186.640 rows=3 loops=1)
Output: ((poi.supplier_product ->> 'supplier_product_name'::text)), poi.price, poi.created_at, ((poi.supplier_product ->> 'supplier_product_manufacturer'::text)), ((poi.supplier_product ->> 'supplier_p
roduct_packing'::text)), ((poi.supplier_product ->> 'supplier_product_pack_quantity'::text)), ((poi.supplier_product ->> 'supplier_product_unit_purchase'::text)), poi.confirmed_quantity, sp.name, sp.identifier, 1
Buffers: shared hit=64024
-> Sort (cost=120195.05..120195.06 rows=1 width=242) (actual time=186.619..186.621 rows=3 loops=1)
Output: ((poi.supplier_product ->> 'supplier_product_name'::text)), poi.price, poi.created_at, ((poi.supplier_product ->> 'supplier_product_manufacturer'::text)), ((poi.supplier_product ->> 'supp
lier_product_packing'::text)), ((poi.supplier_product ->> 'supplier_product_pack_quantity'::text)), ((poi.supplier_product ->> 'supplier_product_unit_purchase'::text)), poi.confirmed_quantity, sp.name, sp.identifier, 1
Sort Key: poi.created_at DESC
Sort Method: top-N heapsort Memory: 26kB
Buffers: shared hit=64024
-> Nested Loop (cost=2.04..120195.04 rows=1 width=242) (actual time=0.193..186.435 rows=273 loops=1)
Output: (poi.supplier_product ->> 'supplier_product_name'::text), poi.price, poi.created_at, (poi.supplier_product ->> 'supplier_product_manufacturer'::text), (poi.supplier_product ->> 'sup
plier_product_packing'::text), (poi.supplier_product ->> 'supplier_product_pack_quantity'::text), (poi.supplier_product ->> 'supplier_product_unit_purchase'::text), poi.confirmed_quantity, sp.name, sp.identifier, 1
Inner Unique: true
Buffers: shared hit=64024
-> Nested Loop (cost=1.75..120194.70 rows=1 width=423) (actual time=0.169..181.896 rows=273 loops=1)
Output: poi.supplier_product, poi.price, poi.created_at, poi.confirmed_quantity, po.supplier_id
Inner Unique: true
Buffers: shared hit=63194
-> Nested Loop (cost=1.31..120192.03 rows=1 width=427) (actual time=0.154..181.249 rows=273 loops=1)
Output: poi.supplier_product, poi.price, poi.created_at, poi.confirmed_quantity, po.supplier_id, bp.base_product_id
Join Filter: ((bp.code)::text = (poi.buyer_product ->> 'buyer_product_code'::text))
Rows Removed by Join Filter: 48357
Buffers: shared hit=62374
-> Nested Loop (cost=0.87..7304.32 rows=6352 width=19) (actual time=0.037..8.088 rows=9209 loops=1)
Output: po.id, po.supplier_id, bp.code, bp.base_product_id
Buffers: shared hit=4649
-> Index Scan using buyer_products_pkey on public.buyer_products bp (cost=0.44..2.68 rows=1 width=15) (actual time=0.016..0.018 rows=1 loops=1)
Output: bp.id, bp.base_product_id, bp.buyer_id, bp.created_at, bp.updated_at, bp.external_id, bp.name, bp.code, bp.status, bp.source_price, bp.identifier, bp.accept_
alternative_brands, bp.id_scub, bp.internal_scub_id, bp.detailed_description, bp.buyer_product_children
Index Cond: (bp.id = 12081956)
Buffers: shared hit=4
-> Index Scan using index_purchase_orders_on_buyer_id on public.purchase_orders po (cost=0.43..7100.53 rows=6704 width=12) (actual time=0.012..6.880 rows=9209 loops=1)
Output: po.id, po.supplier_id, po.total_price, po.items_count, po.created_at, po.updated_at, po.confirmation_id, po.synchronized_at, po.buyer_id, po.observation, po.
sequence, po.origin_id, po.origin_type, po.external_id, po.redirect_to_legacy, po.name, po.origin_observation, po.opened_at, po.contact, po.terms_and_conditions, po.freight_type, po.minimum_purchase, po.valid_until, po.pay
ment_method_id, po.billing_address, po.uuid, po.created_by, po.created_by_info, po.pending_download, po.text_search_vector, po.request_id, po.upload_id, po.upload_id_gr
Index Cond: (po.buyer_id = bp.buyer_id)
Buffers: shared hit=4645
-> Index Scan using index_purchase_order_items_on_purchase_order_id on public.purchase_order_items poi (cost=0.44..9.90 rows=225 width=751) (actual time=0.002..0.006 rows=5 lo
ops=9209)
Output: poi.id, poi.purchase_order_id, poi.created_at, poi.updated_at, poi.status, poi.confirmed_quantity, poi.cancellation, poi.supplier_observation, poi.opening_quantity
, poi.supplier_product, poi.buyer_product, poi.sequence_number, poi.price, poi.comments, poi.origin, poi.uuid, poi.sequence_seller_item_number
Index Cond: (poi.purchase_order_id = po.id)
Filter: (poi.created_at < '2025-02-21 16:57:59.225571'::timestamp without time zone)
Rows Removed by Filter: 0
Buffers: shared hit=57725
-> Index Only Scan using products_pkey on public.products p (cost=0.44..2.68 rows=1 width=4) (actual time=0.002..0.002 rows=1 loops=273)
Output: p.id
Index Cond: (p.id = bp.base_product_id)
Heap Fetches: 0
Buffers: shared hit=820
-> Index Scan using idx_sp_on_id on public.suppliers sp (cost=0.29..0.33 rows=1 width=58) (actual time=0.002..0.002 rows=1 loops=273)
Output: sp.id, sp.name, sp.created_at, sp.updated_at, sp.external_id, sp.identifier, sp.identifier_kind, sp.bio_id, sp.synchronized_at, sp.bioid_synchronized_at, sp.phone, sp.plan_nam
e, sp.metadata, sp.is_external
Index Cond: (sp.id = po.supplier_id)
Buffers: shared hit=828
-> Subquery Scan on "*SELECT* 2" (cost=0.87..5.38 rows=1 width=252) (actual time=0.058..0.060 rows=1 loops=1)
Output: "*SELECT* 2".name, "*SELECT* 2".price, "*SELECT* 2".expires_at, ''::text, ''::text, ''::text, ''::text, 0, ''::character varying, ''::character varying, 2
Buffers: shared hit=8
-> Nested Loop (cost=0.87..5.34 rows=1 width=262) (actual time=0.054..0.055 rows=1 loops=1)
Output: bp_1.name, bp_1.source_price, bp_1.created_at, ''::text, ''::text, ''::text, ''::text, 0, ''::character varying, ''::character varying, 2
Inner Unique: true
Buffers: shared hit=8
-> Index Scan using idx_bp_on_id_source_price on public.buyer_products bp_1 (cost=0.43..2.67 rows=1 width=66) (actual time=0.013..0.013 rows=1 loops=1)
Output: bp_1.id, bp_1.base_product_id, bp_1.buyer_id, bp_1.created_at, bp_1.updated_at, bp_1.external_id, bp_1.name, bp_1.code, bp_1.status, bp_1.source_price, bp_1.identifier, bp_1.accept_
alternative_brands, bp_1.id_scub, bp_1.internal_scub_id, bp_1.detailed_description, bp_1.buyer_product_children
Index Cond: (bp_1.id = 12081956)
Buffers: shared hit=4
-> Index Only Scan using products_pkey on public.products p_1 (cost=0.44..2.68 rows=1 width=4) (actual time=0.005..0.005 rows=1 loops=1)
Output: p_1.id
Index Cond: (p_1.id = bp_1.base_product_id)
Heap Fetches: 0
Buffers: shared hit=4
Query Identifier: 273579094919034765
Planning:
Buffers: shared hit=129
Planning Time: 3.160 ms
JIT:
Functions: 34
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 1.963 ms, Inlining 0.000 ms, Optimization 0.883 ms, Emission 19.683 ms, Total 22.528 ms
Execution Time: 209.321 ms
(82 rows)
Assim como no Oracle Database, o PostgreSQL utiliza a indentação, representada pelo símbolo ->, para indicar a ordem de execução das operações, sem atribuir um identificador sequencial a cada passo. Dessa forma, quanto maior a indentação antes do ->, mais interno (ou profundo) é o passo no plano de execução. Isso significa que os passos mais indentados são executados primeiro.
Com o plano de execução em formato de texto, podemos utilizar as duas ferramentas apresentadas para realizar a análise e identificar possíveis gargalos na execução da query. A seguir, exploraremos ambas as abordagens e demonstraremos como detectar os principais pontos de otimização no SQL.
Utilizaremos o plano de execução em formato de texto gerado anteriormente e o submeteremos à ferramenta Explain Depesz, que apresenta a análise no formato tabular. Você pode acessá-la através do seguinte link: Explain Depesz.
https://explain.depesz.com/

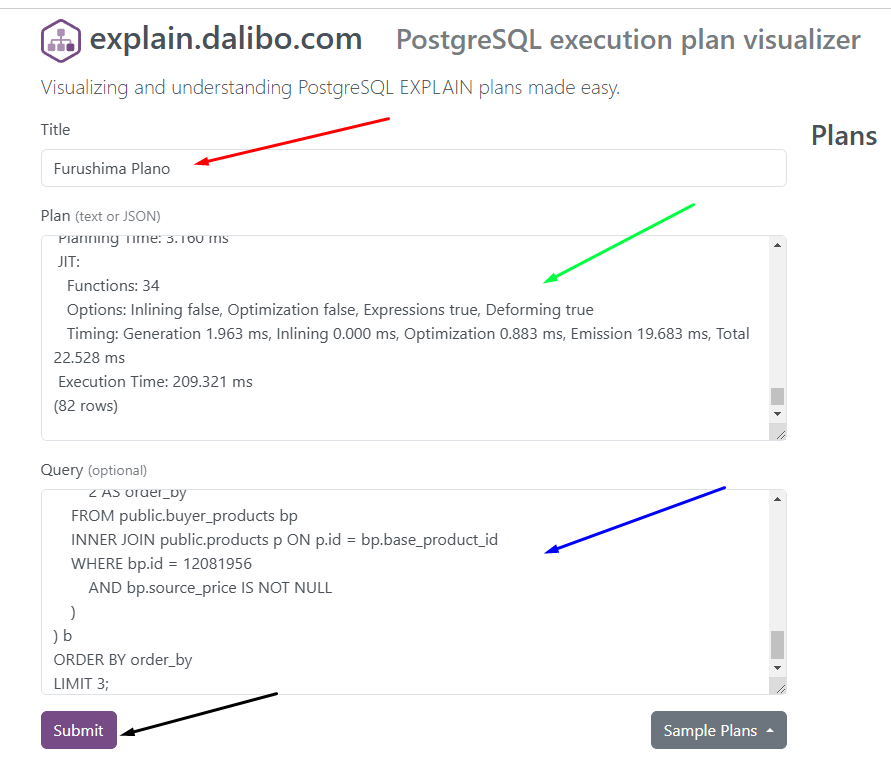
Passos para visualizar o plano de execução no Explain Depesz:
- 🔴 Seta Vermelha: Insira um título para o plano de execução (opcional, mas facilita a organização).
- 🟢 Seta Verde: Cole o plano de execução gerado em formato de texto.
- 🔵 Seta Azul: Cole a query utilizada para gerar o plano de execução.
- ⚫ Seta Preta: Após preencher os campos acima, clique em Submit para processar e visualizar o plano de execução.
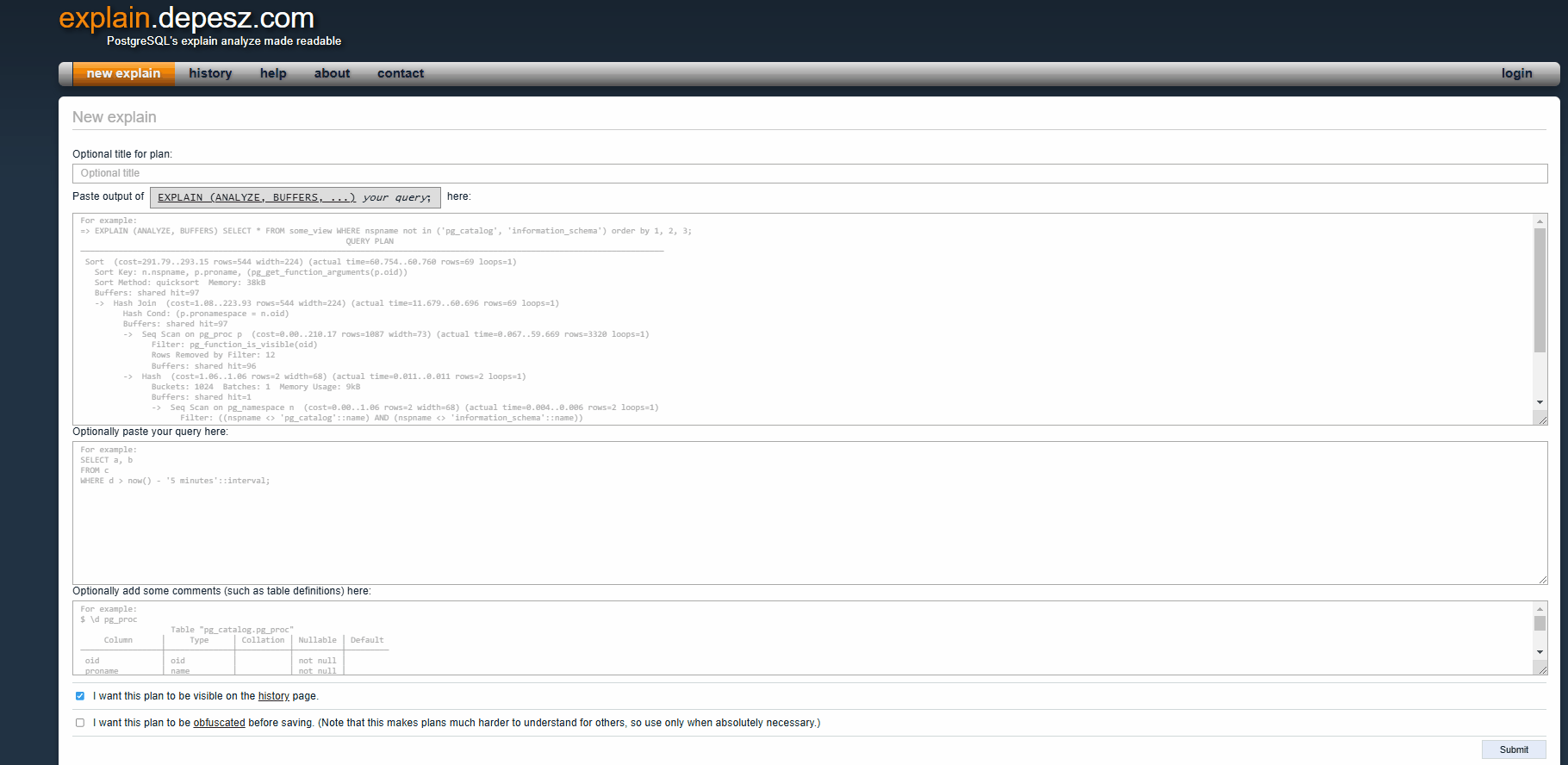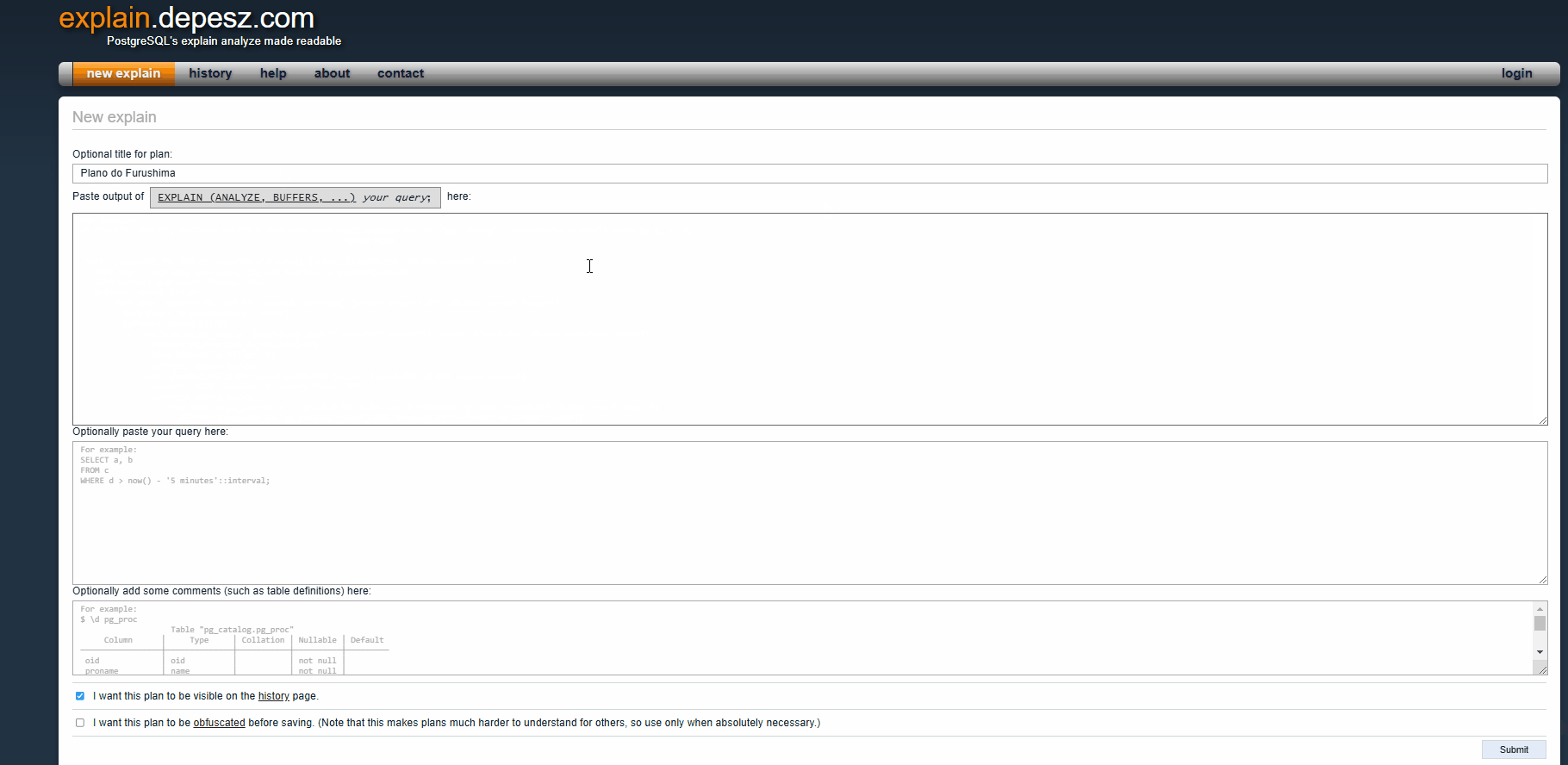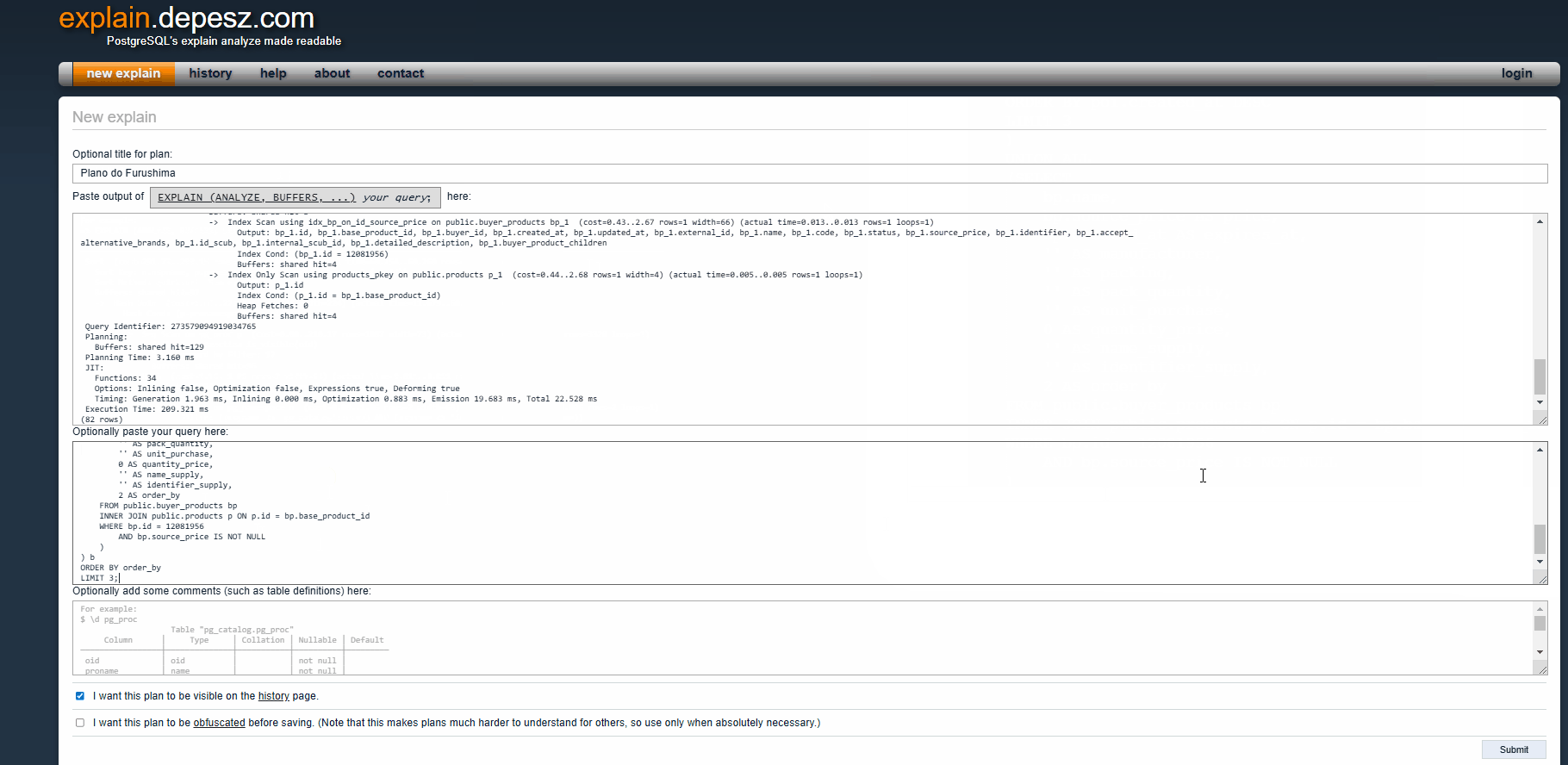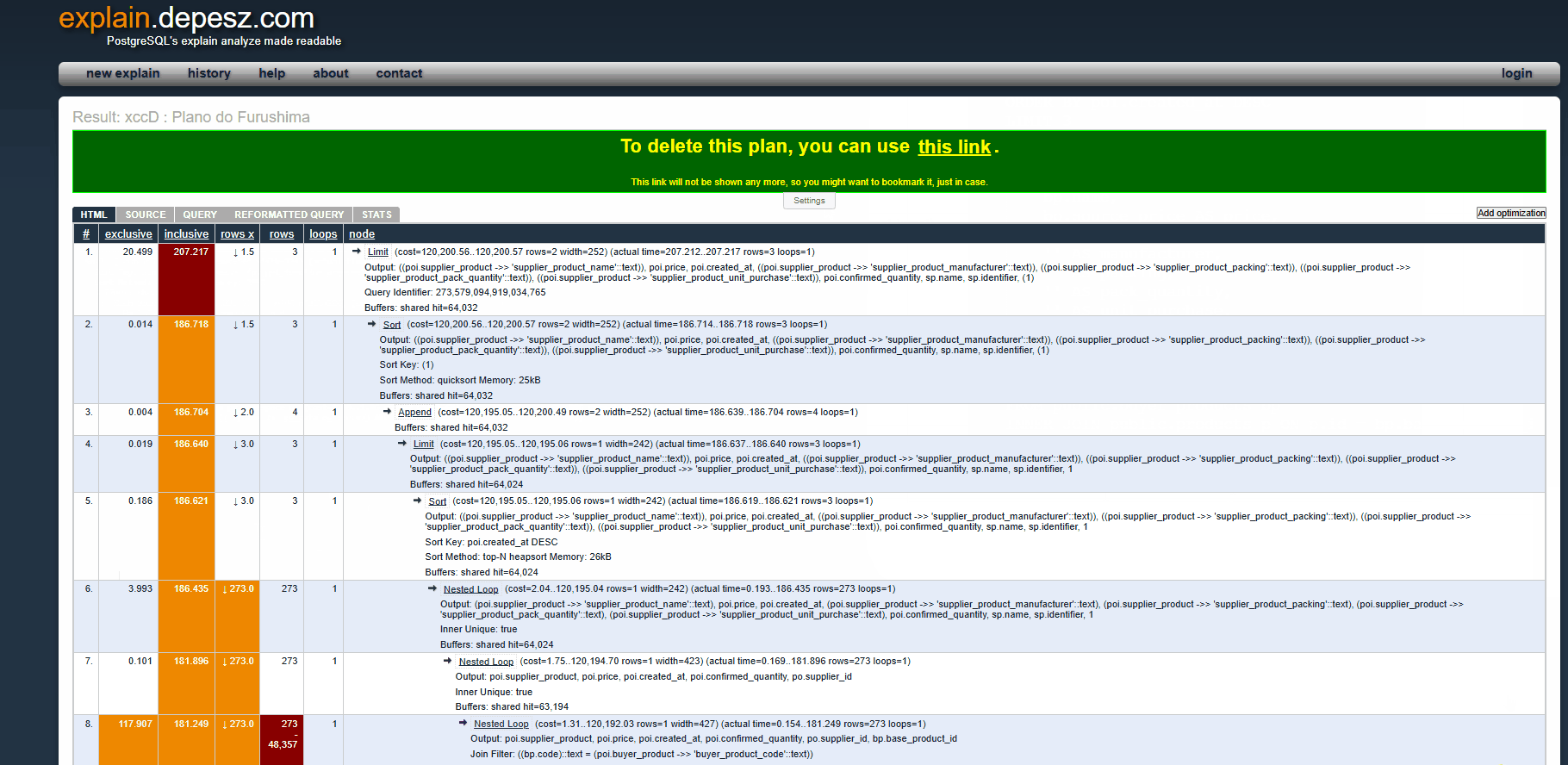
Após submeter o plano de execução, observe na demonstração abaixo os principais gargalos identificados. Eles são destacados em laranja e vermelho, indicando as operações mais custosas. Além disso, os trechos grifados representam cláusulas da query que podem ser otimizadas para melhorar o desempenho.

Nested Loop (cost=1.31..120,192.03 rows=1 width=427) (actual time=0.154..181.249 rows=273 loops=1)
Output: poi.supplier_product, poi.price, poi.created_at, poi.confirmed_quantity, po.supplier_id, bp.base_product_id
Join Filter: ((bp.code)::text = (poi.buyer_product ->> ‘buyer_product_code’::text))
Rows Removed by Join Filter: 48,357
Buffers: shared hit=62,374
📌 O que significa?
- O PostgreSQL está executando um Nested Loop Join para combinar os dados das tabelas buyer_products (bp) e purchase_order_items (poi).
- Custo estimado: 120.192 → Indica que esta é uma das etapas mais pesadas do plano.
- Tempo real gasto: 181.249 ms → Isso confirma que essa operação está realmente demorando muito.
🚨 Problema identificado:
- O Nested Loop Join pode ser ineficiente, especialmente quando muitas linhas precisam ser comparadas.
🔹 Detalhes do Join e o Problema do Filtro
Join Filter: ((bp.code)::text = (poi.buyer_product ->> ‘buyer_product_code’::text))
Rows Removed by Join Filter: 48,357
📌 O que isso significa?
- O PostgreSQL está tentando juntar
bp.codecom o campo JSONpoi.buyer_product ->> 'buyer_product_code'. - Porém, 48.357 linhas foram lidas e removidas porque não atendiam ao filtro.
Isso significa que muitos dados desnecessários foram carregados antes da filtragem.
🚨 Problema identificado:
- O filtro de comparação JSON é extremamente ineficiente.
- O PostgreSQL precisa percorrer todas as linhas antes de saber quais realmente fazem parte da junção.
Buffers: shared hit=62,374
📌 O que isso significa?- 62.374 blocos de memória foram acessados no cache do PostgreSQL.
- Isso indica que nenhuma leitura de disco foi necessária, o que é positivo.
- Porém, mesmo sem leituras de disco, a query ainda está lenta, o que mostra que o problema está na lógica da consulta, não apenas no hardware.
🔹 Como otimizar essa parte do plano?
Agora que sabemos que o Nested Loop Join e o filtro JSON são os principais problemas, podemos sugerir melhorias:
1️⃣ Criar um índice para melhorar a comparação JSON
A comparação (bp.code)::text = (poi.buyer_product ->> 'buyer_product_code'::text) é muito custosa, pois o PostgreSQL precisa processar os dados JSON antes de compará-los.
🚀 Solução: Criar um índice funcional no JSON
CREATE INDEX idx_poi_buyer_product_code ON purchase_order_items ((buyer_product ->> 'buyer_product_code'));
CREATE INDEX idx_poi_purchase_order_id_created_at ON purchase_order_items (purchase_order_id, created_at DESC);
📌 Impacto esperado:
- O PostgreSQL poderá usar o índice diretamente para encontrar as correspondências.
- Reduz drasticamente o número de linhas removidas pelo
Join Filter. - Diminui a necessidade de percorrer todas as linhas da tabela.
- Reduz tempo da busca no
purchase_order_items. - Melhora a performance do
Nested Loop.
📌 Problemas identificados:
- Join Filter está descartando muitas linhas (48.357 removidas).
- Nested Loop Join não é eficiente para grandes volumes de dados.
- Falta de um índice eficiente para buscas no JSON.
- Falta de um índice composto no
purchase_order_itemspara junções rápidas.
🚀 Melhorias sugeridas:
✅ Criar um índice para otimizar a busca JSON.
✅ Usar um Hash Join em vez de Nested Loop.
✅ Criar um índice composto para melhorar as junções.
Melhoria da Análise e Utilização da Ferramenta EXPLAIN DALIBO
Agora que identificamos os gargalos e propomos soluções, vamos abordar esse problema sob uma nova perspectiva, utilizando a ferramenta EXPLAIN Dalibo.


Observe que a caixa do Nested Loop representa o principal gargalo da query, e o “Join Filter” está relacionado à condição ((bp.code)::text = (poi.buyer_product ->> 'buyer_product_code'::text)), o que indica uma junção ineficiente que impacta diretamente o desempenho da consulta.
Conclusão
Neste trabalho, exploramos duas abordagens para analisar e otimizar uma query SQL no PostgreSQL:
- EXPLAIN ANALYZE → Fornece um relatório detalhado sobre a execução da query, ajudando a identificar custos, tempo de execução e estatísticas importantes.
- EXPLAIN Dalibo → Apresenta um formato visual e intuitivo, facilitando a identificação dos pontos críticos da consulta, como Nested Loops, filtros ineficientes e ordenações desnecessárias.
Além disso, aprendemos a identificar gargalos na execução da query, como o Join Filter ineficiente e a ordenção manual sem suporte de índices. Com isso, aplicamos índices estratégicos e sugerimos a troca de algoritmos de junção para melhorar a performance.
O principal aprendizado aqui é que, antes de otimizar uma query, é essencial entender como o PostgreSQL a executa, localizar os gargalos e aplicar ajustes cirúrgicos, como a criação de índices e a escolha do tipo de junção mais eficiente. 🚀
